当前位置:首页 > 资讯中心 > 安徽企划平台-安徽企划行业交流平台 > 正文
OpenAI的对手越追越紧了。
美国当地时间4月18日,Meta发布了Llama 3开源大模型,包括Llama 3 8B和Llama 3 70B。Meta同时透露,目前其最大参数模型已超400B(4000亿)参数,但还在训练。据Meta称,Llama 3是迄今为止功能最强的开源LLM(大语言模型)。在多项基准测试中,Llama 3 70B超过同行。
随着Llama 3发布,开源阵营呈现壮大之势。对于Llama 3的发布,大模型生态社区OpenCSG创始人陈冉向记者表示,竞争会越来越激烈,好现象是大家处于良性竞争。不过未来参数越大,消耗越大,“竞争其实就是钱的竞争”。

Llama 3登场
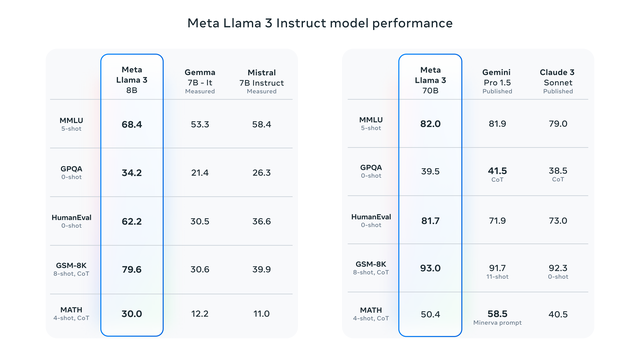
据Meta介绍,Llama 3 8B和70B的推理、代码生成和指令跟踪等功能有大幅改进。Meta使用了超15T tokens(文本单位)的数据训练,训练数据集比Llama 2大7倍,包含的代码多4倍。在开发中,Meta开发了一套新的高质量人类评估集,包含1800个提示并涵盖12个关键用例,如征求建议、头脑风暴、分类、编码等。该评估集的结果显示,Llama 3 70B的表现比Claude Sonnet、Mistral Medium、GPT-3.5、Llama 2更好。
Meta还公布了两个新开源模型与竞争对手比较的情况。在MMLU、GPQA等多项五项基准上,指令微调的Llama 3 8B得分都超过谷歌Gemma 7B-1t和法国初创公司Mistral AI的Mistral 7B Instruct,Llama 3 70B则在三项基准中超过谷歌Gemini Pro 1.5和Anthropic的Claude 3 Sonnet。
不过,Llama 3并非完美,其中被指摘最多的是其上下文窗口只有8k,落后于现在业内平均水平。Meta首席人工智能科学家、图灵奖得主杨立昆(Yann LeCun)在社交媒体发帖同步Llama 3发布的喜讯,而评论区有不少人都在讨论上下文窗口长度只有 8k的信息,“这很令人惊讶,确实限制了实用性”,有热门评论说道。有人质疑为什么Llama 3的上下文窗口与同等模型相比这么小,是架构的限制,还是在训练期间决定优先考虑模型的其他方面,这并未得到杨立昆答复。
外界对Llama 2上下文窗口的关注,背景之一是近两年大模型上下文窗口的文本长度限制已提升明显。更长的上下文这意味着大模型能处理更大范围的文本,更好理解长篇文章或对话,使其在各种应用中更加有用。GPT-3.5上下文窗口文本长度限制为4k,GPT-4提升到32k,GPT-4 turbo版能接收128k输入,基本相当于10万字的小说长度。在国内,零一万物Yi-34B、上海人工智能实验室与商汤科技联合发布的书·浦语2.0等都支持200k长语境输入,月之暗面kimi更支持200万字上下文输入,阿里通义千问免费开放了1000万字长文档处理功能。
对于长上下文窗口的限制,Meta并未直接回应,但在其官方博客里提到,在接下来的几个月里预计将引入新功能、更长的上下文窗口。
对于后续计划,Meta还透露, Llama 3系列还会有更多产品推出,其最大模型超400B参数,该模型还在训练中。
目前,Meta还未透露Llama 3超4000亿参数版本是否会开源。如果该模型开源,将会超过目前参数量最大的开源模型昆仑万维天工3.0(4000亿参数)和马斯克旗下初创公司xAI的Grok-1(3140亿参数)。
业界对Llama 3发布颇为关注。AI写作助手公司HyperWrite AI CEO Matt Shmer感叹“我们正在进入一个新世界,GPT-4级别的模型开源而且可以免费访问”。传奇研究员、AI开源倡导者吴恩达表示,Llama 3发布是自己收到过最好的生日礼物。马斯克也在一条评论Llama 3表现出色的帖文下回复“Not bad(不错)”。
阿里云首席智能科学家丁险峰在社交软件上表示,开源的Llama 3有如安卓,一夜之间打掉所有闭源手机操作系统:PalmOS、Windows mobile、symbian,伟大的时代要来临了。
英伟达科学家Jim Fan则在社交媒体上表示,即将推出的Llama 3 400+B将意味着开源社区获得GPT-4级别的模型开放权重访问,这将是一个分水岭时刻,将改变许多研究工作和初创公司的发展方式。
Jim Fan提取了Anthropic Claude 3 Opus、Open AI GPT-4 Turbo、谷歌Gemini Ultra 1.0和Gemini Pro 1.5的多项基准得分并与Llama 3 400+B早期Checkpoint(检查点)的得分相比,发现Llama 3 400+B多项得分高于Gemini Ultra 1.0和Gemini Pro 1.5,低于但已接近GPT-4和Claude 3 Opus。
猎豹移动董事长兼CEO傅盛则表示,Llama 3性能远超上一代,小参数模型Llama 3 8B的表现比上一代大参数Llama 2 70 B更好,这印证了小参数模型的能力会快速提升,可达到相当高使用水准的说法。Llama 2 70B性能比上一代则有质的提高。预期Llama 3应该代表了开源社区非常高的水准。
也有业界人士使用了Llama 3 8B后表示,原本工具使用稳定性费劲的本地多智能体变得稳定了不少。陈冉则告诉记者,当前国内的开源模型与Llama 3相比或许相差还不小。
OpenAI的对手紧追
OpenAI今年2月发布Sora,成功“狙击”谷歌彼时刚发布的Gemini 1.5并引来更多关注后,似乎难以再压低竞争对手的热度了。OpenAI还未拿出更大“杀器”的情况下,竞争对手的产品升级则是肉眼可见。
有OpenAI最强竞争对手之称的Anthropic今年3月发布了最新大模型系列Claude 3,其中Claude 3 Opus在本科级别专业知识(MMLU)、研究生级别专家推理(G[QA)、基础数学(GSM8K)等领域都超过GPT-4。
Anthropic之外,闭源阵营的OpenAI其他竞争对手则在上探参数量。传言GPT-4参数量上万亿,今年3月,腾讯透露其混元大模型也已达万亿参数规模,近日MiniMax也宣布推出abab 6.5,包含万亿参数。
谷歌、Meta、xAI所属的开源或开闭源双轨并行的阵营也在步步紧逼,参数量越来越大。马斯克指责OpenAI不开源并陷入双方论战后,自己拿出Grok-1。国内也引发一轮开源潮,包括4月初大模型初创企业新旦智能与APUS联手开发的APUS-xDAN大模型4.0(1360亿)参数,以及昆仑万维近日开源的4000亿参数天工3.0。
此次Meta开源的8B和70B参数模型还是小试牛刀,后续或开源的4000亿以上参数大模型,可能是开源阵营的更大“杀器”。
关于开闭源之争近日趋于激烈,也隐隐显露出包括OpenAI在内的闭源阵营,受到开源阵营的一定冲击。相关代表性言论包括百度董事长李彦宏近日所称“大模型开源意义不是很大,有商业模式的闭源模型才能聚集人力和财力”。
支持大模型开源的业界人士则在反击李彦宏的观点。4月18日的生成式AI大会上,vivo AI解决方案中心总监谢伟钦表示,作为产品经理,希望开源社区能逐渐繁荣,出现不同维度的好算法,vivo开源了参数量7B的模型,未来可能还有更大参数的模型开源。
硅基智能CTO林会杰在该会上则表示,开源一定会比闭源好,搜索引擎目前只运行在开源软件上,开源产品的开发效率好,这是无数开发者已验证过的事。同时,开源软件面向更广泛人群,代码质量被更多人看在眼里,不敢开源反而是对自身模型能力不自信的一种表现,很多闭源模型也是建立在开源模型之上。
傅盛也表示:“国内某大厂认为闭源大模型与开源社区的距离越来越远,现实情况正好相反,开源社区公司越来越猛烈。怼算力、怼芯片、只注重参数这条路未必走得通,而且AI不应该是大公司和巨头之间的游戏,应该是所有人都能参与的。我们相信,开源社区必将越战越勇,最终打败闭源大模型。“
闭源和开源阵营竞争对手步步紧逼的情况下,OpenAI的压力很可能变得越来越大。新浪微博新技术研发负责人张俊林认为,大模型巨头混战形成了打压链,OpenAI处于链条顶端,打压有潜力追上的对手,第一层对手包括谷歌、Anthropic和Mistral,第二层是Meta,OpenAI有一个技术储备库,专等竞争对手发布新产品时推出。不过,竞争对手正试图改变被OpenAI打压的情况,此前Anthropic推出Claude 3便可能打乱OpenAI的产品节奏。
张俊林向第一财经记者表示,OpenAI最新推出的是一个音频模型Voice Engine,该模型还在小规模测试阶段,这可能说明OpenAI手里已没太多新东西了,竞争对手已对OpenAI造成比较大压力。
竞争压力下,OpenAI或已经在加快下一代GPT产品研发。3月Claude 3系列发布不久,有网友就发现搜索引擎一度能搜到GPT-4.5 Turbo产品页面,页面摘要显示该模型将在“速度、准确性和可扩展性方面全面超越GPT-4.0 Turbo”,相关页面很快下架。OpenAI如何应对这些竞争,将是下一步看点。
(本文来自第一财经)




